 Вход
Вход Регистрация
Регистрация
|
 Отправлено:
Отправлено:
|
Свободный виртуальный принтер Boomaga - аналог необходимой программы FinePrint (проверен на Linux Mint 17.3)
Boomaga представляет собой виртуальный принтер, помогающий вам просмотреть ваши документы перед печатью на физическом принтере. Позволяет: • Объединить несколько документов • Распечатать несколько страниц на одном листе: 1, 2, 4, 8 страниц на одном листе Буклет. Сложив листы вдвое, вы получите книгу. Установка в Ubuntu: Введите в терминале: sudo add-apt-repository ppa:boomaga sudo apt-get update sudo apt-get install boomaga Если нужно посмотреть, как документ (любой) будет выглядеть после печати, распечатать один или несколько документов в виде книги, или по несколько страниц на лист, иметь двухстороннюю печать на принтере без дуплекса, то все это программа позволяет. Технически это виртуальный принтер для CUPS, при печати на который запускается окно с предпросмотром и возможностью изменения документа. А потом из программы уже можно распечатать на настоящий принтер. Если кто использовал под виндой fineprint, то это оно под *nix. Насколько я знаю, аналогов под никсы нет. Сайт приложения: http://boomaga.github.io/ Последний раз редактировалось: Albert (2016-03-03 09:08), всего редактировалось 1 раз |


|
Как то мне потребовалось скачать информацию со многих URL адресов. Для этого я воспользовался программой Wget.
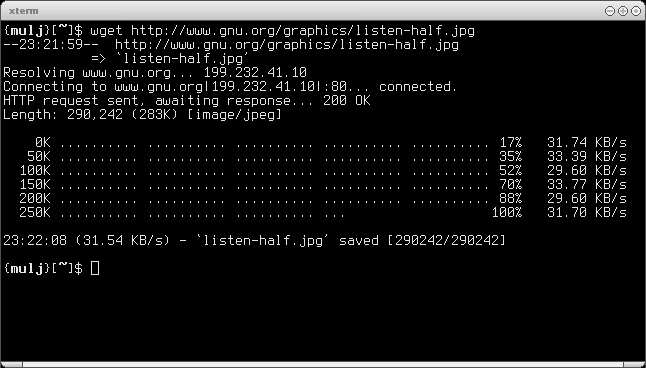
Wget — это (GNU Wget) свободная неинтерактивная консольная программа для загрузки файлов по сети. Поддерживает протоколы HTTP, FTP и HTTPS, а также поддерживает работу через HTTP прокси-сервер. Программа включена почти во все дистрибутивы GNU/Linux. Почитать подробней про нее можно здесь: http://ru.wikipedia.org/wiki/Wget Установка в Ubuntu/Debian (обычно программа входит в состав и установка не требуется). Устанавливается в терминале командой: sudo apt-get install wget Где sudo — выполнение команды с правами администратора, apt-get install — команда для установки пакета wget с репозитория. При выполнении команды закачки в программе Wget, рекомендую указать место закачки используя ключ -P. Например, Вы находитесь в домашней директории, и файл нужно закачать в папку «stream». В домашнем каталоге "user" в папке "Загрузки" создал папку "stream" куда будет загружаться закаченная информация. В папку "Загрузки" помещаю и файл "spisok.txt" В терминале захожу в папку "Загрузки/stream" cd ~/Загрузки/stream Даю команду на закачку файлов из указанных в списке "spisok.txt" URL адресов wget -i ~/Загрузки/spisok.txt Есть портированная версия wget для Windows систем!Доступна она по ссылке: http://sourceforge.net/projects/tumagcc/files/ А чтобы ее установить и с легкостью использовать нужно выполнить всего-лишь десяток простых действий: 1) Скачиваем архив wget с сайта; 2) Создаем папку «wget» в «Program Files» на диске «С:»; 3) Распаковываем содержимое архива в только что созданную папку; 4) Жмем на клавиатуре Windows+Pause/Breake (ну или заходим в свойства системы); 5) Выбираем «Дополнительные параметры системы» 6) Выбираем «Переменные среды» далее выделяем переменную «Path» и жмем «Изменить» 7) Дописываем «;c:\Program Files\wget» (точка с запятой обязательно) и сохраняем. В папке C:\ Program Files\wget помещаем файл “spisok.txt” в котором записаны URL адреса с информацией, которую надо скачать. Например: http://motolebedka.narod.ru/silki-failiy/motolebedka-dacha.pdf http://motolebedka.narod.ru/silki-failiy/_id27_Motoblok_Salut_5.pdf http://motolebedka.narod.ru/silki-failiy/_id27_Kaskad_mb6-84.pdf Создаем папку C:\stream (туда мы будем закачивать информацию). В TotalComander открываем папку c:\Program Files\wget и выполняем (почему-то из cmd не получилось): wget -i spisok.txt -P C:\stream Смотрим содержимое папки C:\stream. Справка по программе: смотрится в cmd. wget --help Скачивание отдельного файла: (Скачается в c:\Users\ХХХ\Wget-screenshot.png) wget -c http://upload.wikimedia.org/wikipedia/commons/3/34/Wget-screenshot.png Скачивание всего сайта: wget -r -l 0 http://open-life.org Скачивание страницы и производных от нее страниц: wget -r -l 6 http://docs.altlinux.org/archive/4.1/desktop/ Число 6 — это глубина поиска составных сайта/страницы, задается ключом "-l". Чем больше глубина — тем больше компонентов страницы и производных от нее страниц скачает Чтобы выкачать файлы из списка, содержащего прямые ссылки: Загрузка всех URL, указанных в файле FILE: wget -i FILE Скачивание файла в указанный каталог (-P): wget -P /path/for/save ftp://ftp.example.org/some_file.iso Использование имя пользователя и пароля на FTP/HTTP: wget ftp://login:password@ftp.example.org/some_file.iso wget --user=login --password=password ftp://ftp.example.org/some_file.iso Скачивание в фоновом режиме (-b): wget -b ftp://ftp.example.org/some_file.iso Продолжить (-c continue) загрузку ранее не полностью загруженного файла: wget -c http://example.org/file.iso Скачать страницу с глубиной следования 10, записывая протокол в файл log: wget -r -l 10 http://example.org/ -o log Скачать содержимое каталога http://example.org/~luzer/my-archive/ и всех его подкаталогов, при этом не поднимаясь по иерархии каталогов выше: wget -r --no-parent http://example.org/~luzer/my-archive/ Для того, чтобы во всех скачанных страницах ссылки преобразовывались в относительные для локального просмотра, необходимо использовать ключ -k: wget -r -l 10 -k http://example.org/ Скопировать весь сайт целиком: wget -r -l 0 -k http://example.org/ Скачивание галереи картинок с превьюшками. wget -r -k -p -l1 -I /images/ -I /thumb/ \ --execute robots=off www.example.com/gallery.html Продолжить скачивание частично скаченного файла wget -c http://www.example.com/large.file Скачать множество файлов в текущую директорию wget -r -nd -np -l1 -A '*.jpg' http://www.example.com/ Отображать вывод напрямую (на экран) wget -q -O- http://www.pixelbeat.org/timeline.html | grep 'a href' | head Скачать url в 01:00 в текущую директорию echo 'wget url' | at 01:00 Сделать закачку с уменьшенной скоростью В данном случае 20 КB/s wget --limit-rate=20k url Проверить ссылки в файле wget -nv --spider --force-html -i bookmarks.html Оперативно обновлять локальную копию сайта (удобно использовать с cron) wget --mirror http://www.example.com/ Используем wildcard для того чтобы скачать несколько страниц wget http://site.com/?thread={1..100} wget http://site.com/files/main.{css,js} Запустить скачивание списка ссылок в 5 потоков cat links.txt | xargs -P 5 wget {} Так вот, если имеется веб-сайт, и хотелось бы иметь его локальную копию на компьютере, чтобы, отключившись от сети, можно было не торопясь его почитать. Зеркалирование сайтов на локальную машину: wget -m http://www.vasyapupkin.com/ -m эквивалентно -r -N -l inf -nr, эти опции описаны ниже. При этом ссылки останутся абсолютными - то есть, будут указывать на Интернет-адреса, и удобно просматривать на локальной машине будет затруднительно. Копирование сайта для локального просмотра (с заменой интернет-ссылок на локальные адреса скачанных страниц): wget -r -l0 -k http://www.vasyapupkin.com/ При этом будет включена рекурсивная выгрузка (ключ -r, –recursive), Опции -np, –no-parent — не подниматься выше начального адреса при рекурсивной загрузке. -r, –recursive — включить рекурсивный просмотр каталогов и подкаталогов на удал©нном сервере. -l <depth>, –level=<depth> — определить максимальную глубину рекурсии равной depth при просмотре каталогов на удалённом сервере. По умолчанию depth=5. -np, –no-parent — не переходить в родительский каталог во время поиска файлов. Это очень полезное свойство, поскольку оно гарантирует, что будут копироваться только те файлы, которые расположены ниже определённой иерархии. -A <acclist>, –accept <acclist>, -R <rejlist>, –reject <rejlist> — список имен файлов, разделенных запятыми, которые следует (accept) или не следует (reject) загружать. Разрешается задание имен файлов по маске. -k, –convert-links — превратить абсолютные ссылки в HTML документе в относительные ссылки. Преобразованию подвергнутся только те ссылки, которые указывают на реально загруженные страницы; остальные не будут преобразовываться. Заметим, что лишь в конце работы wget сможет узнать какие страницы были реально загружены. Следовательно, лишь в конце работы wget будет выполняться окончательное преобразование. –http-user=<user>, –http-passwd=<password> — указать имя пользователя и пароль на HTTP-сервере. -H, –span-hosts — разрешает посещать любые сервера, на которые есть ссылка. -p, –page-requisites — загружать все файлы, которые нужны для отображения страниц HTML. Например: рисунки, звук, каскадные стили (CSS). По умолчанию такие файлы не загружаются. Параметры -r и -l, указанные вместе могут помочь, но т.к. wget не различает внешние и внутренние документы, то нет гарантии, что загрузится все требуемое. |
{kind=link}
Текущее время: 26-Май 10:00
Часовой пояс: UTC + 3
|
Вы не можете начинать темы
Вы не можете отвечать на сообщения Вы не можете редактировать свои сообщения Вы не можете удалять свои сообщения Вы не можете голосовать в опросах Вы не можете прикреплять файлы к сообщениям Вы можете скачивать файлы |